The Trillion Row Challenge: Comparing AWS Serverless Big Data Platforms
Eskild Eriksen
Data Engineer • February 20, 2024

Benchmarking AWS Serverless Big Data Platforms: A Comprehensive Analysiss
In our latest exploration, we set out to benchmark three prominent AWS serverless big data platforms: Dask cluster running on ECS Fargate, Spark cluster running on AWS Glue Jobs, and Spark cluster running on EMR Serverless. Our goal was to understand how these platforms stack up against each other in terms of cost and performance, particularly when dealing with massive datasets.
These are important questions that we consider when evaluating the best tool for a given use case. There are many other factors to consider, including flexibility, maintainability, ease of use, and integration with existing system. Our benchmarking exercise aims to provide insight into how we use data to help us make informed decision as we work with clients draw real, effective value out of their data.
Inspired by the One Trillion Row Challenge shared by Coiled, we aim to calculate the min, mean, and max temperature per weather station from a dataset stored in Parquet format on S3, totaling a staggering one trillion rows. This blog post shares our findings, assumptions, and insights to help you decide which solution might be the best fit for your needs.
Benchmarking Methodology
Each platform was tested using a similar setup to ensure a fair comparison:
- Compute Capacity: 4 vCPU and 16 GB memory across 50 workers
- Dataset: A trillion rows, 2.5 TB, stored in Parquet format on S3
- Metrics: Total runtime (including startup and shutdown) and average cost across three runs
Results
AWS ECS Fargate running Dask
ECS Fargate prices can be found here.
HOURS_TO_SECONDS = 3600
data = {
# in seconds
'Runtime (s)': [
1303, # Run 1: 21mins 43secs
1242, # Run 2: 20mins 42secs
1330, # Run 3: 22mins 10secs
],
}
dask = pd.DataFrame(data)
total_workers = 50
dask_memory_gb = 16
dask_vcpu = 4
dask_memory_gb_price = 0.004445
dask_vcpu_price = 0.04048
dask_cost_rate = total_workers * (
(dask_memory_gb * dask_memory_gb_price) + (dask_vcpu * dask_vcpu_price)
)
dask[f'Cost ($)'] = dask.apply(
lambda x: dask_cost_rate * x['Runtime (s)'] / HOURS_TO_SECONDS, axis=1
)| Run | Runtime | Cost |
|---|---|---|
| 1 | 21mins 43secs | $4.22 |
| 2 | 20mins 42secs | $4.02 |
| 3 | 22mins 10secs | $4.30 |
AWS Glue Job running Spark
Glue Job prices can be found here.
We can enable "Flexible Execution" to reduce costs by up to 34%.
data = {
# in seconds
'Runtime (s)': [
1637, # Run 1: 27mins 17secs
1572, # Run 2: 26mins 12secs
1596, # Run 3: 26mins 36secs
],
}
glue = pd.DataFrame(data)
dpus = 50
dpu_hour_rate = 0.44
glue_cost_rate = dpus * dpu_hour_rate
glue[f'Cost ($)'] = glue.apply(
lambda x: glue_cost_rate * x['Runtime (s)'] / HOURS_TO_SECONDS, axis=1
)| Run | Runtime | Cost |
|---|---|---|
| 1 | 27mins 17secs | $10.00 |
| 2 | 26mins 12secs | $9.61 |
| 3 | 26mins 36secs | $9.75 |
AWS EMR Serverless running Spark
EMR Serverless prices can be found here.
data = {
# in seconds
'Runtime (s)': [
1340, # Run 1: 22mins 20secs
1284, # Run 2: 21mins 24secs
1303, # Run 3: 21mins 43secs
],
}
emr = pd.DataFrame(data)
total_workers = 50
emr_memory_gb = 16
emr_vcpu = 4
emr_memory_gb_price = 0.0057785
emr_vcpu_price = 0.052624
emr_cost_rate = total_workers * (
(emr_memory_gb * emr_memory_gb_price) + (emr_vcpu * emr_vcpu_price)
)
emr[f'Cost ($)'] = emr.apply(
lambda x: emr_cost_rate * x['Runtime (s)'] / HOURS_TO_SECONDS, axis=1
)| Run | Runtime | Cost |
|---|---|---|
| 1 | 22mins 20secs | $5.64 |
| 2 | 21mins 24secs | $5.40 |
| 3 | 21mins 43secs | $5.48 |
Analysis
Our benchmarking revealed significant differences in both performance and cost across the platforms. Dask on ECS Fargate proved to be the most cost-effective and consistently performed well in terms of runtime. AWS Glue Jobs was both the most expensive option, and the least performant. EMR Serverless was closer to Dask on ECS in terms of both cost and performance.
plt.figure(figsize=(10, 6))
plt.plot(dask['Runtime (s)'], dask['Cost ($)'], label='ECS running Dask', marker='o')
plt.plot(
glue['Runtime (s)'], glue['Cost ($)'], label='Glue Job running Spark', marker='^'
)
plt.plot(emr['Runtime (s)'], emr['Cost ($)'], label='EMR running Spark', marker='s')
plt.xlabel('Runtime (s)')
plt.ylabel('Cost ($)')
plt.title('Runtime vs. Cost for Three Datasets')
plt.legend()
plt.grid(True)
plt.show()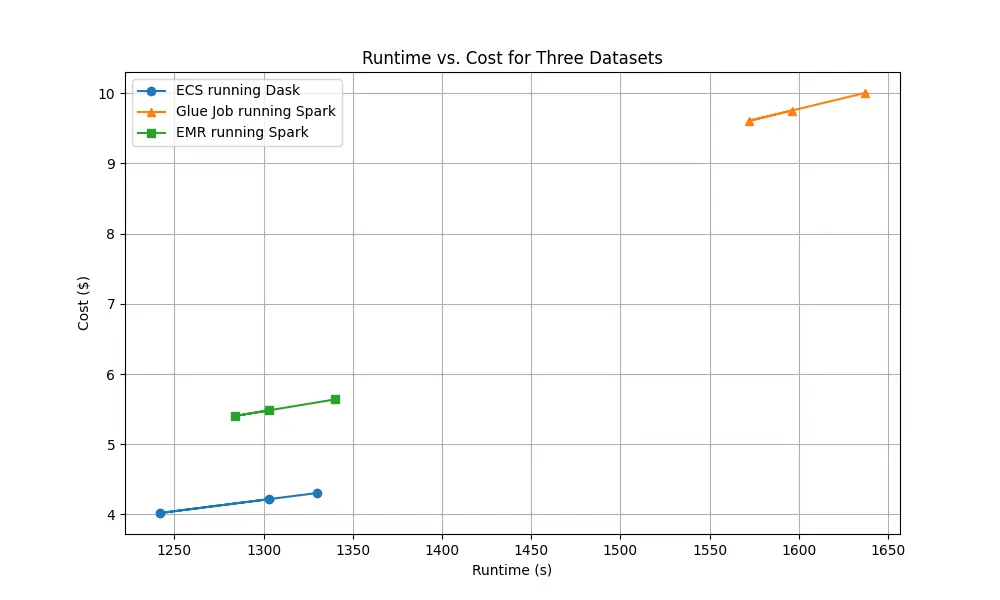
Assumptions and Considerations
Given that these platforms are serverless, we did not consider the cost of the underlying infrastructure, such as S3 storage and data transfer costs. We also tried to ensure that all 50 workers were running simultaneously. In practice, this might not be the case, and there are many other decisions to make around the chunk size, memory, and CPU allocation, which could impact the cost and performance; we tried to avoid those complexities in this analysis.
Choosing the Right Platform
If minimizing cost is a primary concern, Dask on ECS Fargate appears to be the most cost-effective solution followed by EMR Serverless. Your existing technology stack and familiarity with Spark or Dask might influence your choice. AWS Glue Jobs and EMR Serverless are more tightly integrated with the AWS ecosystem, which might be a deciding factor for teams already heavily invested in AWS. Dask on ECS will likely require the most maintenance and setup, but it offers the most flexibility and control over your environment, while also integrating well with other PyData tools.
Conclusion
Our benchmarking exercise offers valuable insights into the cost and performance of leading AWS serverless big data platforms. While each platform has its strengths and weaknesses, the final decision should be based on your specific use case, budget constraints, and performance needs. We hope this analysis aids in your decision-making process as you navigate the complexities of big data processing on AWS.