It All Starts With Data: Is your data ready for AI and LLM-based applications?
Greg Dolder
Head of Engineering • December 31, 2024

You can't read an article, watch a video or see any product/software ad without the constant inundation of AI and how it's the answer to all our problems. While this is not the case, you can't help but be excited to see the potential of AI and LLMs to solve real-world problems.
Given this, we can't help but notice when it comes to AI, there is one unshakeable truth: it all starts with data. If your data is garbage your outcomes are bound to be garbage. Regardless of how you slice it - whether you're using Retrieval Augmented Generation (RAG), Agentic AI, or any other techique/technology - poor data will always lead to poor outcomes.
At productOps, we know that pristine data is the bedrock of any successful AI Initiative (or any other project for that matter). Through years of experience, we've seen the impact of poor data on the success of AI and non-AI initiatives alike. Your efforts to include data strategy, governance, cleansing and curation in your AI solution will pay dividends in the quality and reliability of your solution(s).
Why Data Quality Matters
- Bias and Inaccuracy: Inconsistent or incomplete datasets cause your AI models to learn patterns that don’t reflect real-world scenarios. For instance, if your data underrepresents certain customer segments, your predictive models might favor one demographic over another, leading to skewed insights and recommendations.
- Data Gaps & Hallucinations: Generative AI tools like RAG rely on comprehensive, accurate data to produce fact-based outputs. If the underlying data is missing key information or riddled with inaccuracies, the AI may “hallucinate” results—essentially making up facts or drawing flawed conclusions. Spending time on this early in your project will save you exponentially in the long run. Follow the Rule of 10 (graphic below showing cost of when bugs/issues are found)) to help you plan your data efforts around AI.
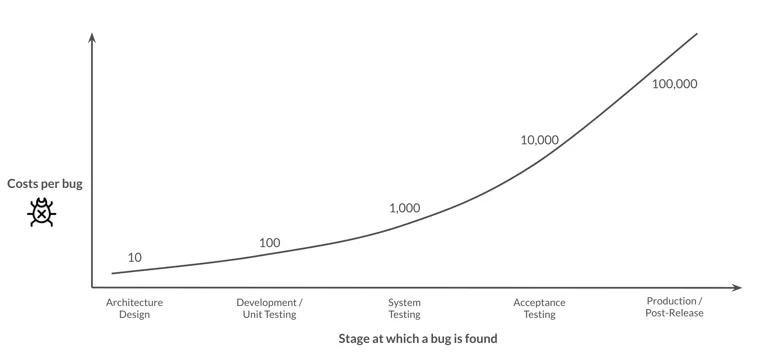
- Agentic AI Failures: When your AI agents rely on poor data, their decision-making logic is compromised. An agent meant to optimize scheduling could produce schedules that ignore critical constraints (like workforce availability or inventory levels), ultimately creating inefficiencies and mistrust among users.
- Wasted Time & Resources: AI solutions demand significant investments—infrastructure, staffing, licensing, and more. When those systems train on low-quality data, your ROI plummets. You may end up spending even more time and money to fix or retrain your models.
- Reputational Damage: Faulty AI-driven recommendations or misleading insights can damage customer trust. Whether you’re a B2C brand or a B2B powerhouse, releasing flawed AI-driven features can erode credibility overnight.

What does bad data look like?
- Inconsistent Formatting & Values: Some entries/data may list states inconsistently "New York" vs "N.Y." vs "NY" for example.
- Inaccurate Labels: Mis-categorized images or product IDs can throw off entire computer vision or product recommendation pipelines. This is unfortunately more common than anyone wants to admit.
- Missing or Duplicate Data: Gaps in transactional data or double entries cause confusion and inflates or understates key metrics.
- Unreliable Source Data: Relying on unverified third-party data for market insights can introduce misinformation that corrupts your predictive modeling.
- Outdated & Irrelevant Data: Using stale data about customer preferences leads to irrelevant recommendations or marketing campaigns.
Real-Wold Examples of Poor Data Leading to Poor Results
- Recommendation Systems: An eCommerce platform that uses incomplete transaction history might recommend products the user already owns or has no interest in, driving down conversion rates.
- Financial Forecasting: When a machine learning model relies on erroneous or out-of-date market indicators, it can produce risk assessments that leave businesses underprepared for volatility.
- Language Models: A chatbot trained on a biased corpus could perpetuate offensive language or stereotypes, resulting in PR nightmares.
The productOps Approach
- Data Audit & Cleansing: Conduct a thorough audit of your data to identify potential pitfalls, resolve quality issues, pinpoint missing values, duplicates, inconsistencies and more. The time spent here pays dividends in the long run, refer to the 10X rule ;)
- Data Governance Framework: Utilize robust data governance frameworks to ensure your data stays clean over time. Strong data governance helps you avoid recurring issues and assists in compliance with data regulations & standards.
- Scalable Data Architecture: From data pipelines to storage solutions, build scalable architectures that evolve alongside your busiiness. As your data needs grow or augment, your architecture will be ready.
- Continuous Optimization: Don't just buid it and walk away. Continually monitor and optimize data quality to your AI or other projects for optimal performance and accuracy. Refer to the OODA loop below for more information.
The OODA Loop
The OODA loop is a decision-making process that involves observing, orienting, deciding, and acting. It's a cycle that helps you make decisions. In the context of data and AI, the OODA loop is a way to continuously improve your data quality and AI outcomes.
- Observe - Gather data and insights from your data and AI initiatives.
- Orient - Analyze the data and insights to understand the current state and identify areas for improvement.
- Decide - Develop a plan to improve the data and AI outcomes.
- Act - Implement the plan and monitor the results.
